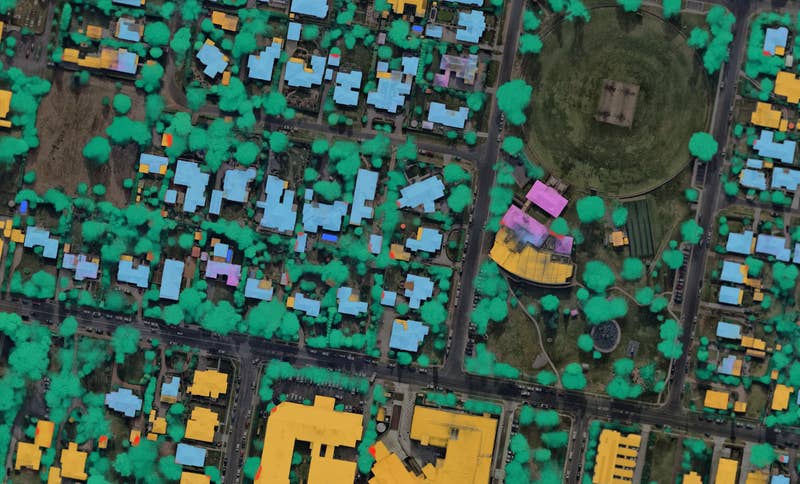
Introducing Nearmap for Post-catastrophe Response
Post Catastrophe Imagery and AI-derived property damage and condition data unite to help insurers process customer claims more efficiently.
Post Catastrophe Imagery and AI-derived property damage and condition data unite to help insurers process customer claims more efficiently.
In the previous post, we made qualitative comparisons between our 2018 Nearmap AI vegetation coverage, and the 2018/2019 Green Adelaide LiDAR study. Visual inspection of side-by-side zoomed-in results showed that both techniques very effectively capture tree canopy.
While qualitative assessments can provide intuitive insights into how a data set works, it can be difficult to see the forest for the trees. Broader trends in how a data set behaves need to be captured and assessed in a quantitative manner not visible at the scale of a single suburb.
Beyond providing assurance on the consistency of the Nearmap AI methodology, this comparison also illustrates the necessary differences required to translate between methodologies. This becomes particularly important when concrete, tangible targets are involved. If a council has a target to reach 30% tree cover, what does this mean? At a basic level, is it a target for tree cover in residential areas, or are neighbouring parks included? If every methodology has a different baseline and bias, what assumptions are included about how that target is measured?
It is our intention that Nearmap AI tree canopy allows us to move beyond these definitional questions, to focus on the matter of what to do about it! The consistency, ubiquitous availability, and ability to track through time means the same result can be used in every urban environment, and act as a reference against which other, more custom studies can be adjusted.
In this post, we examine statistics on aggregated data at the LGA level, and compare in a quantitative fashion Nearmap AI to two other existing data sets:
The Hort Innovation/RMIT results. Columns used for tree cover percent of LGAs were “Tree2013”, “Tree2016”, “Tree2020”.
The Green Adelaide LiDAR LGA levels. The column used for tree cover percent of LGAs was “CanopyCover”.
In order to complete a equivalent ‘apples-to-apples’ comparison between the Nearmap AI results and other data sets, we adjusted our analysis to:
The following comparisons were used:
| Other Data Source | Nearmap AI Season |
Green Adelaide LiDAR 2018/2019 |
Jan-Mar 2018 |
Hort Innovation (i-Tree) 2013 |
Jan-Mar 2013 |
Hort Innovation (i-Tree) 2016 |
Jan-Mar 2016 |
Hort Innovation (i-Tree) 2020 |
Jan-Mar 2020 |
Once all LGAs had been recalculated from the relevant season, only the list of LGAs covering both data sets, with full Nearmap AI coverage from that season were used. This included a wide range of total tree cover, from approximately 10% to over 30%.
The relative difference Δ for each comparison between the Nearmap AI measurement and the other data set was calculated as:
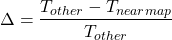
In the graph below, each dot represents a single LGA. The colour of the dots indicates which data set comparison was being made. The vertical location of the dots shows the relative difference as a point plot, accompanied by the boxplot in the same colour alongside it (representing a summary of the same data).
The following graph shows the equivalent data to the boxplots above, just focusing on the 2018 Nearmap AI vs LiDAR comparison. Nearmap data is represented in blue – triangles for raw tree cover level, and squares (with +/- 2.5% relative error bars) for data shifted up by a relative 18% to best match the LiDAR data. Based on the agreement between the iTree analysis and Nearmap AI data in the above graph, the true value is likely to be the Nearmap AI result, so it would be better to shift the LiDAR down.
The relative difference exhibited very tight correlation (standard deviation 5.32%), centred around a median difference of -18.1% (where the Nearmap measurement was 18% below the LiDAR measurement), and mean difference of -17.5%. The only outlier was the LGA with smallest coverage (Port Adelaide Enfield), where the value lay around 10%.
The relative differences exhibited much looser correlation, with a standard deviation across all three time points of 11.15%. The means were much closer, however, with a median difference of +1.9%, mean difference +1.1%.
Systematic Differences
A systematic difference is a consistent, repeatable difference between two methodologies that is caused by a difference in methodology. ‘Bias’ would be another word commonly used to describe this concept. One example would be the difference between a human starting a race manually with a stop watch, and an electronic automated system. The human has a natural reaction time, and there will therefore always be a delay in the manual timing compared to the automated one.
For a canopy cover assessment, the most likely cause of systematic differences comes down to definition. Subtle differences in definition of what constitutes a tree (whether deliberate or a limitation of the sensing system), if applied consistently to a data set, can have a large impact.
There is clearly a strong, systematic difference between the Nearmap AI and LiDAR results. With a paired t-test between the two measurements having a p-value of 0.00003, it is statistically improbable that the differences are due to random variation. Pooling all three time points for the i-Tree analysis data, there is insufficient evidence to suggest a meaningful difference (bias) between the two data sets (p-value of 0.73).
The strong disagreement between Nearmap AI and LiDAR results can possibly be explained due to edge effects on trees. The visual inspection in part 3 of this series found that both methodologies reliably capture the trees. However, they exhibited different artefacts (notably the 1 square metre grid on which the LiDAR was computed), particularly on the edges of trees.
Our hypothesis is that these edge effects are sufficient to explain the offset. In the image below, the orange perimeter enlarges the total area of the circle by 18%. Visually, it looks like a small difference, but this is due to it being distributed around the perimeter. From the visual assessment in the previous post, it is certainly plausible that this difference is present, either due to the blocky nature of the 1 square metre processing grid, or simply the different sensor technology causing a more generous interpretation of tree edges. The cause cannot be determined without careful quantitative analysis of the raw data, but the effect is clear — if Nearmap AI results indicate a tree canopy cover of 20%, the LiDAR study would indicate 23.6%. This may not be a problem with year-on-year change analysis (if a consistent methodology is applied). But could have very tangible results if absolute tree cover targets are being discussed.

The lack of evidence that the Nearmap AI and i-Tree data differ is suggestive of the fact that there is no significant bias between the two. This appears sensible, given the i-Tree analysis relied on human experts assessing points on Nearmap images. What is particularly interesting is that Nearmap AI was trained against a very high volume of labelled data, on a slightly different tree canopy definition, using totally independent set of labelling experts and software systems. A difference of only 1% is encouraging, in that the minor differences in tree definition, training and methodology appeared to have negligible impact.
Data set variance
The variance, or spread of the data is a second important point of comparison. Interestingly, the roles are reversed.
Between the LiDAR and Nearmap AI, the standard deviation is 5.3% (2.7% if the outlier is removed). Despite the large systematic difference, the consistency between the two methodologies is remarkable. One interpretation is that there is in fact a very strong agreement in the definition of “what is a tree” between the two (despite one using imagery and deep learning, and the other using laser pulses and heuristic algorithms). If the cause was differences in treatment of different tree species, or tree heights, a much weaker correlation could be expected. The “simple” difference of an 18-19% offset is easily resolved.
The standard deviation between the Nearmap and i-Tree results is much larger, at 11.15%.
Our hypothesis is that this is caused by the sampling approach of the i-Tree study (as compared to counting every square metre of ground in the LGA).
If 1,000 random points were used in each LGA for a yes/no tree decision, this can be approximated by a binomial distribution. The standard deviation of the tree cover percent is then analogous to the standard error of the proportion in electoral polling (which by common rule of thumb is +/-3% with 1,000 samples). It can be calculated by ![]() , where p is the percent tree cover, and n is the number of samples (1,000). The source document helpfully provides a table of these pre-calculated for the RMIT 2020 data.
, where p is the percent tree cover, and n is the number of samples (1,000). The source document helpfully provides a table of these pre-calculated for the RMIT 2020 data.
Assuming the Nearmap AI result is the true value, the average of these (when converted to relative percentage) is 10.9%. The Standard deviation for the Nearmap AI vs RMIT 2020 data was a very close 11.35%. This means that the random variation caused by only taking 1,000 random samples per LGA is entirely sufficient to explain the difference between the i-Tree and Nearmap AI data.
The benefit here is that much less random variation means that stronger claims can be made about individual results, both at absolute levels and detecting changes. While the i-Tree study makes use of paired results to increase its power to detect change, this is still not as powerful as measuring every square metre of the area of interest.
2m vs 3m Tree Canopy Definitions
A specific note on the commonly raised question of 2m vs 3m definitions for canopy. With the above analysis in mind, if this was an issue that had meaningful impact on the percent cover, we would expect Nearmap AI to have higher results (by including 2-3m height trees that the LiDAR ignores). On the contrary, the LiDAR results are a systematic 18-19% higher than the Nearmap AI ones.
By comparing the Nearmap AI tree canopy results against two other entirely different methodologies (data sets captured by different organisations, independently, at different points in time), we can reach some quantitative conclusions:
-----
Some LGAs list the same suburb as both the 'greenest suburb' and 'least green suburb'. This means that there was only a single residential suburb within the LGA fully covered by the analysis.
Nearmap does not warrant or accept any liability in relation to the accuracy, correctness or reliability of the data provided as part of the Nearmap Leafiest Suburbs analysis. The Nearmap Leafiest Suburbs analysis is based on Nearmap AI data, which detects trees approximately 2m or higher. The national aerial data was collected Oct 2020-March 2021. Results were aggregated at mesh block level using the 2021 Australian Bureau of Statistics definitions. Approximately 5,000 suburbs were included in the analysis, where Nearmap AI coverage exceeded 99%. The top suburbs are those with the greatest percent tree cover in each 2021 SA4 region, and where there is a minimum population of 1,000 residents (2016 census). For suburbs that span multiple LGAs, that suburb is assigned to the LGA that contains the highest proportion of that suburb’s area. City-based metrics analyse all Nearmap AI covered suburbs within the relevant ABS GCCSA region. For the capital city suburb breakdowns, we also refined the analysis to only include ‘residential’ mesh blocks. All percentage figures have been rounded to the closest whole number.
------
About the author:
With degrees in electrical engineering and physics — and a passion for machine learning — Dr Michael Bewley joined Nearmap in 2017 as our first data scientist. Now the Senior Director of AI Systems, he leads the development of the Nearmap artificial intelligence product suite, quantifying the evolution of cities with the most superior AI data sets.
* 281 suburbs within greater Adelaide were included in the analysis, where Nearmap AI coverage exceeded 99%. The analysis includes each suburb where there is a minimum population of 1,000 residents (2016 census).
Analysis fundamentals
The fundamental aspects of the national study were reused for consistency. Key points include:
While we make every effort to ensure the accuracy of the data and analysis in blog articles, this information is not to be relied on as professional advice. No endorsement or approval of any third parties or their advice, opinions, information, products or services is expressed or implied by any information in the blog. Should you seek to rely in any way whatsoever upon this content, you do so at your own risk.


